
楽音における音色知覚特徴の分析とモデリング
原題: Analysis and Modeling of Timbre Perception Features in Musical Sounds
Received: 2019年12月25日 / Accepted: 2020年1月20日 / Published: 2020年1月22日
本論文は、楽器音色を評価するための新しい用語体系を含む、音色知覚特徴の分析およびモデリングのための新規手法を提案する。構築されたデータベースは、反対極性の5組を含む16個の専門家・一般向け評価用語から成る。さらに、72サンプルからなる素材ライブラリ(中国民族管弦楽器37種、中国少数民族楽器11種、西洋管弦楽器24種)と、54サンプルの客観音響パラメータ集合を整備した。
主観評価には系列カテゴリー法を用いた。そのうえで、音色知覚特徴、すなわち「明るい/暗い」「干瘪した/柔らかい」「鋭い/渾厚な」「粗い/純粋な」「しわがれた/協和的な」を、線形回帰、サポートベクタ回帰、ニューラルネットワーク、ランダムフォレストを用いて初めて数理モデル化した。実験結果は、提案モデルがこれらの属性を高精度に予測できることを示した。
最後に、改良された3次元音色空間構築法を提案した。この3D音色空間の聴覚知覚属性は、各空間次元と16個の音色評価用語との相関を分析することで決定された。
キーワード: 特徴抽出、音色モデリング、聴覚知覚、音色空間
1. 序論
音の主観的知覚は、ラウドネス、ピッチ、音色という3つの聴覚属性に由来する [1]。近年、研究者たちはラウドネスとピッチについては比較的成熟した評価モデルを確立してきたが [2,3]、音色の定量的計算と評価ははるかに複雑である。研究によれば、音色は音楽的感情を伝えるうえで重要な音響手がかりであり、音楽、音声、環境音を人が認識・分類する際の重要な基盤でもある [4]。そのため、音色の定量分析とパラメータ化モデルの確立は、視聴覚情報処理、音楽検索、感情認識の分野において大きな意義をもつ。
音色の主観的性質は評価過程を難しくしており、通常は主観評価、信号処理、統計分析に依存する。American National Standards Institute (ANSI) は、音色を「同じラウドネスとピッチで提示された2つの音が異なると聴取者が判断できる、その聴覚感覚の属性」と定義している [5]。これは、音色が楽音を区別する重要因子であることを示している [6]。
音色評価用語、すなわち音色形容詞は、音色知覚特徴を記述するうえで重要な指標である。そのため、包括的で代表性のある用語体系は、実験的な聴覚知覚データの信頼性を確保するうえで不可欠である。従来の音色評価研究は、音楽・言語音質、道路交通騒音制御、自動車・航空機エンジン騒音評価、音響機器の音質設計、サウンドスケープ評価の分野で進められてきた。これらのうち、英語圏での研究は比較的成熟しており、表1に示すような蓄積がある。しかし、国籍、文化的背景、慣習、言語、環境の違いは、音色評価用語の認知に必然的に影響する [7-11]。また、中国楽器は構造、製作材料、発音機構の点で西洋楽器と大きく異なり、その音色は西洋楽器よりもさらに多様である。したがって、既存の英語による音色評価用語だけでは、その微妙な差異を十分に記述できない可能性がある。ゆえに、中国楽器研究において、音楽音色評価用語の構築は大きな意義をもつ。
| 著者 | 年 | 評価対象 | 評価語数 |
|---|---|---|---|
| Solomon [12] | 1958 | 20種類の受動ソナー音 | 50組 |
| von Bismarck [13] | 1974 | 35種の有声・無声音、楽音 | 30組 |
| Pratt and Doak [14] | 1976 | 管弦楽器(弦、木管、金管を含む) | 19 |
| Namba et al. [15] | 1991 | 「展覧会の絵」の《プロムナード》4演奏 | 60 |
| Ethington and Punch [16] | 1994 | 電子シンセサイザーが生成した音 | 124 |
| Faure et al. [17] | 1996 | 12種の合成西洋伝統楽器音 | 23 |
| Iwamiya and Zhan [9] | 1997 | 市販CDからの24音楽断片 | 18組 |
| Howard and Tyrrell [18] | 1997 | 西洋管弦楽器、音叉、オルガン、やわらかく歌われた音 | 21 |
| Shibuya et al. [19] | 1999 | ヴァイオリンによるA長調音階(弓圧3、弓速3、発音点3) | 20 |
| Kuwano et al. [20] | 2000 | 体系的に制御された48種の合成警告音 | 16組 |
| Disley and Howard [21] | 2003 | 4種のオルガン録音 | 7 |
| Moravec and Štepánek [22] | 2003 | 管弦楽器(弓奏、管、鍵盤) | 30 |
| Collier [23] | 2004 | 170種のソナー音(人工9、生物14、合計23発生源タイプ) | 148 |
| Martens and Marui [24] | 2005 | 9種の歪んだギター音 | 11組 |
| Disley et al. [25] | 2006 | MUMSライブラリの12楽器サンプル(木管、金管、弦、打楽器) | 15 |
| Stepánek [26] | 2006 | 同一奏法で演奏されたヴァイオリン音 B3, #F4, C5, G5, D6 | 25 |
| Katz and Katz [27] | 2007 | 音楽録音作品 | 27 |
| Howard et al. [28] | 2007 | MUMSライブラリの12楽器サンプル(弦、金管、木管、打楽器) | 15 |
| Barbot et al. [29] | 2008 | 14種の航空機音(離陸と到着を含む) | 90 |
| Pedersen [30] | 2008 | 反応を喚起するあらゆる刺激 | 631 |
| Alluri and Toiviainen [31] | 2010 | インドのポピュラー音楽100断片(各1.5秒) | 36組 |
| Fritz et al. [32] | 2012 | ヴァイオリン音 | 61 |
| Altinsoy and Jekosch [33] | 2012 | 異なるブランド・モータリゼーションの24車種×8走行条件の音 | 36 |
| Elliott et al. [34] | 2013 | 42種の管弦楽器録音(必要に応じてミュート・ビブラート版を含む) | 16組 |
| Zacharakis et al. [35] | 2014 | 3オクターブにまたがる23種の音(アコースティック、電気、シンセ) | 30 |
| Skovenborg [36] | 2016 | ポップやロック等の商業前マスターやライブ録音など70録音/ミックス | 30 |
| Wallmark [37] | 2019 | 管弦楽器(木管、金管、弦、打楽器) | 50 |
音色には音源に関する複雑な情報が含まれており、人間はそれを聞くことで対象を認識する一連の課題を実行できる [38]。そのため、音色知覚特性の定量分析と記述は、楽器認識 [39]、音楽感情認識 [40]、歌唱品質評価 [41]、アクティブソナー反響検出 [42]、水中目標認識 [43] など、軍事・民生の両分野で広い意義をもつ。音色知覚特徴の数理モデルを構築することは、音色を定量的に記述するうえで重要である。
従来、音色知覚特徴を定量化する手法は大きく2つあった。1つは心理音響パラメータの概念である [6]。人間の耳の聴覚特性を解析することで、鋭さ、粗さ、変動強度などの主観的感覚を表現する数学モデルを構築する方法である [44]。しかし、これらの研究で用いられた刺激信号の多くは雑音であり、楽音に対して計算された値は主観感覚と一致しないことが多く、適用範囲が限定的で片面的であった。もう1つは、主観評価実験と統計分析を組み合わせる手法である。知覚特徴の差異に基づいて実験を設計し、そこから客観パラメータを抽出し、統計分析または機械学習によって客観パラメータと知覚特徴の対応関係を確立し、最終的に知覚特徴の数理モデルを構築する。この方法は音色モデリング [45,46]、音楽情報検索 [47]、楽器分類 [48]、楽器の協和性評価 [49]、車室内音評価 [50]、水中目標認識 [42] などで広く使われている。ただし、これらの研究で用いられた実験材料は主に西洋楽器や雑音であった。中国楽器は発音機構や奏法が独特であり、豊かな音色変化を有するため、より完全な音色知覚モデルを構築するには、中国楽器を刺激として用いる必要がある。
音色は多次元の聴覚属性であり、連続的な音色空間として表現できる。この構造は音の特性の定量分析と分類にとって重要である。初期の音色空間研究では意味差分法が使われた [12,13]。近年は、非類似度に基づく多次元尺度構成法(MDS)が音色空間の構築に使われている。たとえば Grey は16種の西洋楽器音サンプルから3次元音色空間を構築した [51]。McAdams らは合成音を用いて音色空間の共通次元を研究し、空間次元と対応する音響パラメータの関係を明らかにした [52]。Martens らはギター音色を用いて、言語背景による音色空間の差異を研究した [53,54]。Zacharakis と Pastiadis は、16種の西洋楽器を用いた主観評価と分析から、輝度-テクスチャ-質量(LTM)モデルを提案した [55]。Simurra と Queiroz は、13組の対義的言語属性に基づく尺度評価を33種の管弦楽断片に対して行い、質量、明るさ、色、散在性など、触覚・視覚的性質に関連した主要知覚カテゴリを抽出した [56]。
しかし、MDS による音色空間の構築には、各サンプル間の非類似度行列が必要である。従来法では、サンプルを2つずつ比較する一対比較法によって非類似度を取得しており、実験負荷が大きく、専門性の要求も高く、評価尺度の制御が難しかった。本論文では、系列カテゴリー法に基づいて非類似度行列を間接的に計算する新しい音色空間構築法を提案し、作業量を削減するとともに、データの安定性と信頼性を高めた。本論文の構成は次のとおりである。第2節で音色ライブラリの構築過程、第3節で音色評価用語の構築、第4節で知覚特徴モデル、第5節で音色空間構築を述べ、第6節で結論を示す。研究方法の全体像は図1に示す。

図中要素の日本語要約: 「音色データベース構築」では録音・編集・ラウドネス正規化を行う。「音色評価用語体系構築」では音色評価語シソーラスの構築と実験Aを通じて、16個の専門家向け評価語と5組の一般向け評価語を得る。「音色知覚特徴モデル構築」では客観音響パラメータ抽出、実験B、主観・客観データの機械学習による対応付けを行う。「音色知覚空間構築」では実験C、音色空間構築、空間次元の属性分析を行う。
2. 音色データベースの構築
2.1. 音色素材の収集
高品質な音色素材データベースを構築するため、実験に必要な素材をすべて、背景騒音レベル -2 dBA の完全無響室で録音した。使用機材は BK 4190 自由音場マイクロホンと BK LAN-XI3560 AD コンバータである。演奏者は音楽学院の教員および大学院生であった。録音内容は音階と個別の楽曲断片から成る。音声編集には Avid Pro Tools HD を使用した。各クリップの長さは6〜10秒、サンプリング周波数は44,100 Hz、量子化精度は16 bit、保存形式は .wav であった。
従来の音色研究では主に西洋楽器が刺激素材として使われてきた。しかし、音色知覚特徴の精度を高めるには、できるだけ多様な音色サンプルが必要である。そこで本研究では、72種類の異なる楽器、すなわち中国民族管弦楽器36種、中国少数民族楽器12種、西洋管弦楽器24種を用いて音色の多様性を確保した。72楽器の名称とカテゴリは付録Aに示す。このデータから72個の音声ファイルからなる音色ライブラリを構築した。
2.2. ラウドネス正規化
音色の定義に従えば、音色研究ではしばしばピッチとラウドネスの影響を除外する。しかし先行研究によれば、場合によっては音色とピッチは独立ではない [57]。そのため、本論文で扱う音色知覚特徴にはピッチ要因も含まれる。一方でラウドネスの影響を除去するため、平衡実験を用いて、実験結果に基づく音色素材のラウドネス正規化を行った [58]。
3. 音色主観評価用語体系の構築
まず32個の評価語から成る音色評価語彙集を構築し、強制選択法に基づく主観音色評価実験(実験A)を実施した。クラスタ分析の結果を統合することで16個の代表的音色評価語を選び、さらにこれら16語の相関分析を行った。相関係数が0.85を超える6語は削除し、残った10語を反対極性をもつ5組にまとめた(相関係数の絶対値が0.81以上)。この5組は、系列カテゴリー法に基づく音色評価実験(実験B)および音色知覚特徴のパラメトリックモデリングに用いた。
3.1. 音色評価語シソーラスの構築
等価音条件下で音色評価語の徹底的な調査を行った。文献調査とアンケートから合計329語を収集した。その後、音楽の専門的背景をもつ5名が、主観実験に適さないと判断した155語(多義的、意味が曖昧、複合語など)を削除した。残った174語について、21名の音楽専門家が音声クリップを聴き、それぞれがその音の記述に適しているかどうかを判断した。最終的に頻度の高い32語を選び、32個の音色指標から成る語彙表を作成した(表2)。これらの用語は音色ダイナミクスのあらゆる側面を記述しうるが、冗長情報も含んでいたため、統計分析によってさらに整理する必要があった。
| 暗淡 (Dark) | 饱满 (Plump) | 纯净 (Pure) | 粗糙 (Coarse) |
| 丰满 (Full) | 干瘪 (Raspy) | 干涩 (Dry) | 厚实 (Thick) |
| 尖锐 (Sharp) | 紧张 (Intense) | 空洞 (Hollow) | 明亮 (Bright) |
| 生硬 (Rigid) | 嘶哑 (Hoarse) | 透亮 (Clear) | 透明 (Transparent) |
| 粗涩 (Rough) | 单薄 (Thin) | 低沉 (Deep) | 丰厚 (Rich) |
| 厚重 (Heavy) | 浑厚 (Vigorous) | 混浊 (Muddy) | 尖利 (Shrill) |
| 清脆 (Silvery) | 柔和 (Mellow) | 柔软 (Soft) | 沙哑 (Raucous) |
| 温暖 (Warm) | 纤细 (Slim) | 协和 (Consonant) | 圆润 (Fruity) |
3.2. 実験A: 強制選択法に基づく主観評価実験
実験は、残響時間0.3秒で聴取基準 [59] を満たす標準聴取室で行った。参加者は音楽の専門的背景をもつ41名(男性21名)で、年齢は18〜35歳、難聴歴はなかった。強制選択法を採用し、素材ライブラリの音声クリップを順次再生し、各評価語がその音を記述するのに適切かどうかを被験者に判断させた。その後、クラスタ分析と相関分析を用いて実験データを評価し、専門家向け音色評価体系(16語)と、一般向け音色評価体系(反対極性の5組)を構築した。
3.3. 実験Aのデータ分析と結論
まず、多次元尺度を用いて、32個の評価語間の距離関係を2次元空間で分析した。図2に32語の距離関係を示す。図2から、一部の領域では評価語間距離が小さく、高い相関があることが分かる。以後の音色知覚特徴モデリングの負担を軽減するため、さらにクラスタ分析により評価語の次元削減を行った。図3は、系統クラスタ法により得られたクラスタ樹形図である。この図と先に得た選択頻度を用いて、32語を16個の音色評価語に統合した(表3)。これら16語は、後の音色空間モデリング(実験C)で用いる専門家向け音色評価体系となった。
| 暗淡 (Dark) | 尖锐 (Sharp) | 协和 (Consonant) | 纯净 (Pure) |
| 粗糙 (Coarse) | 清脆 (Silvery) | 纤细 (Slim) | 单薄 (Thin) |
| 丰满 (Full) | 混浊 (Muddy) | 柔和 (Mellow) | 干瘪 (Raspy) |
| 厚实 (Thick) | 明亮 (Bright) | 嘶哑 (Hoarse) | 浑厚 (Vigorous) |
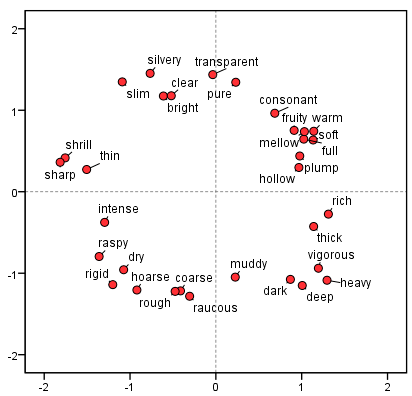
図中ラベル例: silvery = 清脆、transparent = 透明、bright = 明亮、pure = 纯净、consonant = 协和、warm = 温暖、soft = 柔软、full = 丰满、plump = 饱满、raspy = 干瘪、dry = 干涩、hoarse = 嘶哑、rough = 粗涩、coarse = 粗糙、muddy = 混浊、dark = 暗淡、deep = 低沉、vigorous = 浑厚、rich = 丰厚、sharp = 尖锐、shrill = 尖利。

次に、これら16語の Pearson 相関係数(PCC)を計算することで、一般向け音色評価用語体系を構築した。PCC が0.85を超える相関の高い6語を除外し、残る10語について相関行列を求めた(表4)。この行列から、負の相関または絶対値の大きい相関をもつ用語を選び、反対意味をなす評価語ペアを形成した。こうして10語を5組にまとめた(表5)。この5組が一般向け音色評価体系を構成し、実験Bと音色知覚特徴のパラメトリックモデリングに用いられた。
| Bright | Dark | Sharp | Vigorous | Raspy | Coarse | Hoarse | Consonant | Mellow | Pure | |
|---|---|---|---|---|---|---|---|---|---|---|
| Bright | 1.00 | -0.99 | 0.90 | -0.93 | 0.24 | -0.48 | -0.31 | 0.13 | -0.27 | 0.47 |
| Dark | -0.99 | 1.00 | -0.89 | 0.93 | -0.20 | 0.49 | 0.33 | -0.17 | 0.26 | -0.48 |
| Sharp | 0.90 | -0.89 | 1.00 | -0.93 | 0.58 | -0.14 | 0.06 | -0.24 | -0.57 | 0.17 |
| Vigorous | -0.93 | 0.93 | -0.93 | 1.00 | -0.43 | 0.31 | 0.09 | 0.06 | 0.37 | -0.28 |
| Raspy | 0.24 | -0.20 | 0.58 | -0.43 | 1.00 | 0.61 | 0.74 | -0.83 | -0.82 | -0.51 |
| Coarse | -0.48 | 0.49 | -0.14 | 0.31 | 0.61 | 1.00 | 0.89 | -0.82 | -0.55 | -0.92 |
| Hoarse | -0.31 | 0.33 | 0.06 | 0.09 | 0.74 | 0.89 | 1.00 | -0.86 | -0.62 | -0.83 |
| Consonant | 0.13 | -0.17 | -0.24 | 0.06 | -0.83 | -0.82 | -0.86 | 1.00 | 0.79 | 0.75 |
| Mellow | -0.27 | 0.26 | -0.57 | 0.37 | -0.82 | -0.55 | -0.62 | 0.79 | 1.00 | 0.51 |
| Pure | 0.47 | -0.48 | 0.17 | -0.28 | -0.51 | -0.92 | -0.83 | 0.75 | 0.51 | 1.00 |
| 名称 | 相関係数 |
|---|---|
| 明亮–暗淡 (Bright–Dark) | -0.99 |
| 干瘪–柔和 (Raspy–Mellow) | -0.82 |
| 尖锐–浑厚 (Sharp–Vigorous) | -0.93 |
| 粗糙–纯净 (Coarse–Pure) | -0.92 |
| 嘶哑–协和 (Hoarse–Consonant) | -0.86 |
4. 音色知覚特徴モデルの構築
166次元の客観音響パラメータを音声サンプルから抽出した後、系列カテゴリー法による音色知覚評価実験(実験B)を実施し、その結果データの信頼性・妥当性を分析した。さらに、線形回帰、サポートベクタ回帰、ニューラルネットワーク、ランダムフォレストを用いて音色知覚特徴モデルを構築し、その精度を評価するとともに、新しい音素材に対する知覚特徴予測に適用した。
4.1. 客観音響パラメータ集合の構築
音色は時間波形とスペクトル構造に密接に関連する多次元知覚属性である [60]。音色知覚特徴モデルを構築するため、音色データベースから抽出した54個のパラメータを用いて客観音響パラメータ集合を構築した。客観音響パラメータとは、時間領域および周波数領域における通常音信号を表現する数学モデルから得られる値である。これら54パラメータは6カテゴリに分類できる [61]。
- 時間形状特徴: 波形または信号エネルギー包絡から計算される特徴(アタック時間、時間的増減、実効持続時間など)。
- 時間特徴: 自己相関係数とゼロ交差率。
- エネルギー特徴: 信号の各種エネルギー量(全エネルギー、倍音エネルギー、雑音エネルギーなど)。
- スペクトル形状特徴: STFT の振幅スペクトルから計算される特徴(重心、広がり、歪度、尖度、傾き、ロールオフ周波数、MFCC など)。
- 倍音特徴: 正弦波倍音モデリングにより計算される特徴(倍音/雑音比、奇数/偶数倍音比、トリスティミュラス比、倍音偏差など)。
- 知覚特徴: 人間の聴覚モデルに基づいて計算される特徴(相対比特定ラウドネス、鋭さ、拡がり)。
4.2. 計算方法
主な音響パラメータの計算式は以下のとおりである。
式(1) スペクトル重心 C_t = (Σ[n=1..N] M_t[n] × n) / (Σ[n=1..N] M_t[n]) M_t[n] はフレーム t、周波数 n におけるフーリエ変換の振幅である。重心値が大きいほど、より「明るい」音とみなされる。
式(2) スペクトル傾斜
slope(t_m) = (1 / Σ[k=1..K] a_k(t_m)) ×
(K Σ[k=1..K] f_k a_k(t_m) - (Σ[k=1..K] f_k)(Σ[k=1..K] a_k(t_m)))
/ (K Σ[k=1..K] f_k^2 - (Σ[k=1..K] f_k)^2)
ここで a_k は k におけるスペクトル振幅、f_k は k における周波数である。
式(3) トリスティミュラス T1(t_m) = a_1(t_m) / Σ[h=1..H] a_h(t_m) T2(t_m) = (a_2(t_m) + a_3(t_m) + a_4(t_m)) / Σ[h=1..H] a_h(t_m) T3(t_m) = Σ[h=5..H] a_h(t_m) / Σ[h=1..H] a_h(t_m) H はパーシャルの総数、a_h は h 番目パーシャルの振幅である。
式(4) スペクトルフラックス
spectral flux = 1 - (Σ[k=1..K] a_k(t_m-1) a_k(t_m))
/ sqrt((Σ[k=1..K] a_k(t_m-1)^2) (Σ[k=1..K] a_k(t_m)^2))
スペクトルフラックスは時間に伴うスペクトル変動の程度を表す。
式(5) 非整数倍音度
inharmo(t_m) = {2 Σ[h=1..H] (f_h(t_m) - h f_0(t_m)) a_h(t_m)^2}
/ {f_0(t_m) Σ[h=1..H] a_h(t_m)^2}
f_0 は基本周波数、f_h は h 番目パーシャルの周波数である。
式(6) スペクトルロールオフ Σ[f=0..f_c(t_m)] a_f^2(t_m) = 0.95 Σ[f=0..sr/2] a_f^2(t_m) f_c(t_m) は信号エネルギーの95%を含むカットオフ周波数である。
式(7) 奇数/偶数倍音エネルギー比 OER(t_m) = Σ[h=1..H/2] a_(2h-1)^2(t_m) / Σ[h=1..H/2] a_(2h)^2(t_m)
54個のパラメータに対し、最大値、最小値、平均、分散、標準偏差、四分位範囲、歪度、尖度など12種類の時間変動統計量を計算し、166次元の客観音響パラメータ集合を作成した(表6)。特徴抽出には Timbre Toolbox [62] と MIRtoolbox [66] を用いた。音色データベース素材から対応する音響パラメータを抽出し、得られたデータを音色知覚特徴モデル構築に用いた。
| 特徴名 | 数 | 特徴名 | 数 |
|---|---|---|---|
| 時間特徴: Log Attack Time | 1 | 倍音スペクトル形状: Harmonic Spectral Centroid | 6 |
| Temporal Increase | 1 | Harmonic Spectral Spread | 6 |
| Temporal Decrease | 1 | Harmonic Spectral Skewness | 6 |
| Temporal Centroid | 1 | Harmonic Spectral Kurtosis | 6 |
| Effective Duration | 1 | Harmonic Spectral Slope | 6 |
| Signal Auto-Correlation Function | 12 | Harmonic Spectral Decrease | 1 |
| Zero-Crossing Rate | 1 | Harmonic Spectral Roll-off | 1 |
| エネルギー特徴: Total Energy | 1 | Harmonic Spectral Variation | 3 |
| Total Energy Modulation | 2 | 知覚特徴: Loudness | 1 |
| Total Harmonic Energy | 1 | Relative Specific Loudness | 24 |
| Total Noise Energy | 1 | Sharpness | 1 |
| スペクトル特徴: Spectral Centroid | 6 | Spread | 1 |
| Spectral Spread | 6 | 知覚スペクトル包絡形状: Perceptual Spectral Centroid | 6 |
| Spectral Skewness | 6 | Perceptual Spectral Spread | 6 |
| Spectral Kurtosis | 6 | Perceptual Spectral Skewness | 6 |
| Spectral Slope | 6 | Perceptual Spectral Kurtosis | 6 |
| Spectral Decrease | 1 | Perceptual Spectral Slope | 6 |
| Spectral Roll-off | 1 | Perceptual Spectral Decrease | 1 |
| Spectral Variation | 3 | Perceptual Spectral Roll-off | 1 |
| MFCC | 12 | Perceptual Spectral Variation | 3 |
| Delta MFCC | 12 | Odd-to-Even Band Ratio | 3 |
| Delta Delta MFCC | 12 | Band Spectral Deviation | 3 |
| 倍音特徴: Fundamental Frequency | 1 | Band Tristimulus | 9 |
| Fundamental Frequency Modulation | 2 | 各種特徴: Spectral Flatness | 4 |
| Noisiness | 1 | Spectral Crest | 4 |
| Inharmonicity | 1 | Total Number of Features | 166 |
| Harmonic Spectral Deviation | 3 | Odd-to-Even Harmonic Ratio | 3 |
| Harmonic Tristimulus | 9 | — | — |
4.3. 実験B: 系列カテゴリー法に基づく音色評価実験
主観評価実験は、残響時間0.3秒で聴取基準 [59] に適合する標準聴取室で行った。参加者は音楽の専門的背景をもつ34名(男性16名)で、年齢は18〜35歳、難聴歴はなかった。実験手続きは次のとおりである。素材断片を再生し、被験者は各音色知覚特徴(評価語)について順にその心理尺度を判断し、9段階尺度で評定した。正式実験前に全素材を再生し、各被験者がサンプルに事前に慣れるようにした。これは評価基準と評定尺度の理解を助け、同一サンプルに対する評価データのばらつきを減らすためである。各素材は2回再生され、再生間隔は5秒、サンプル長は6〜10秒であった。各評価語の試行時間は10分で、30分ごとに15分の休憩を設けた。
34名分のデータについて信頼性と妥当性を分析し、各被験者の評定間の相関係数を算出した。さらに、クラスタ分析により評価語間のユークリッド距離を求め、各群で差が最も大きい2名の被験者を特定した。実験目的の理解が不十分であった一部被験者のデータは除外し、後続のモデリングには用いなかった。続いて、系列カテゴリー法 [67] により実験データを統計処理した。この方法は、心理尺度を正規分布に従う確率変数とみなし、各カテゴリ境界も事前固定値ではなく、実験データから同定される確率変数とする。最後に Thurstone 尺度によりデータを処理し、全音色素材と各知覚特徴に対する心理尺度を算出した。図4に、72種の楽器を5つの音色評価次元で表した心理尺度を示す。各図における点線は、対応する次元における各楽器群の平均値を表す。
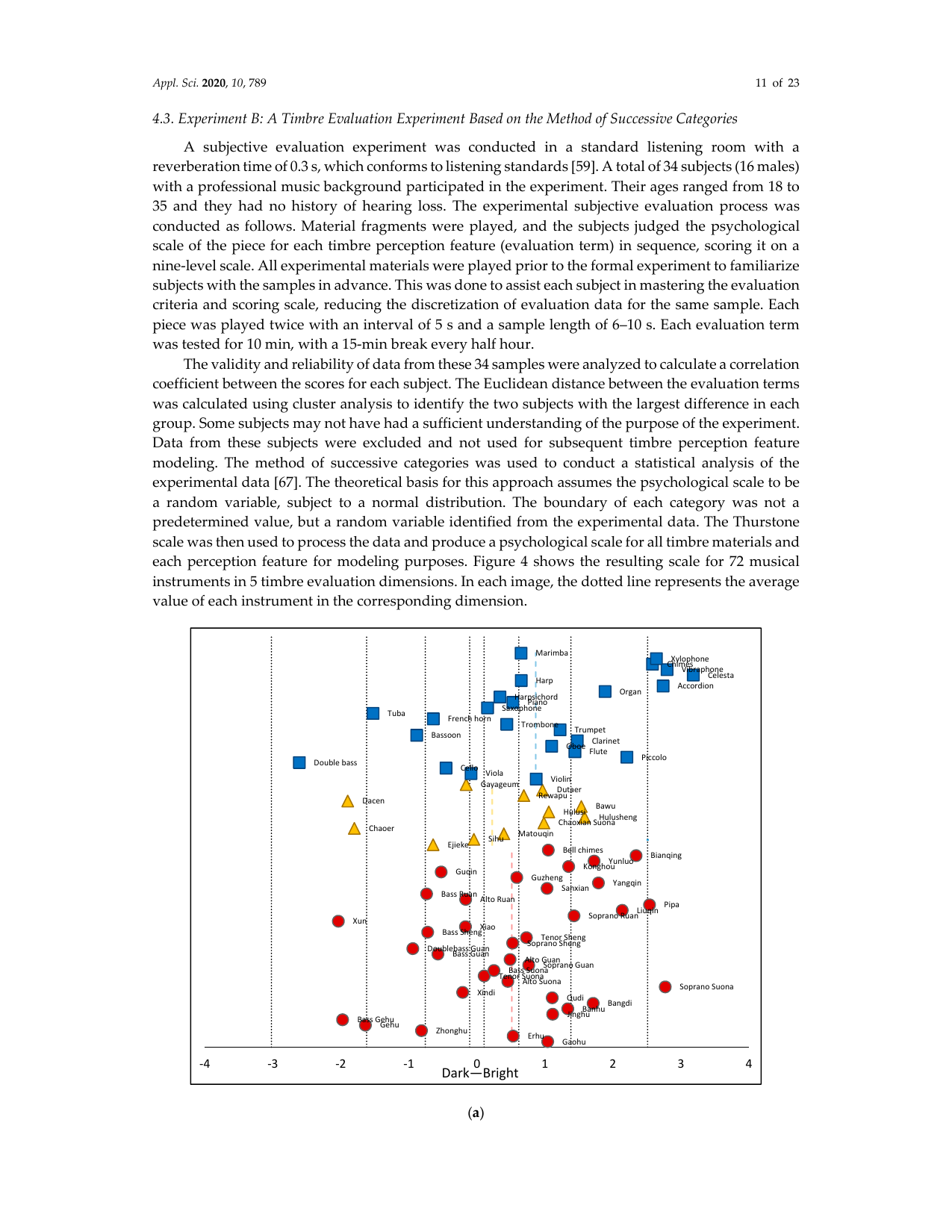
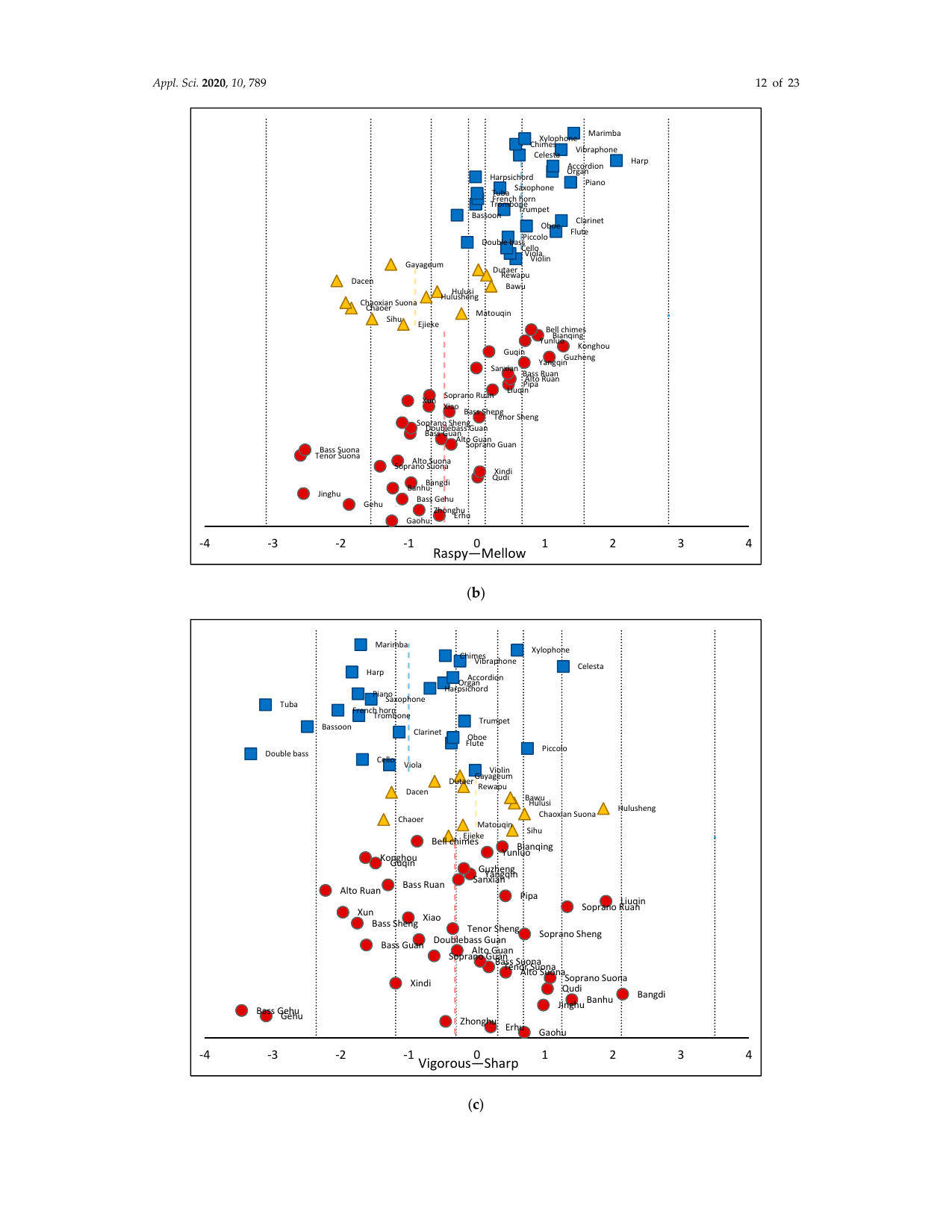
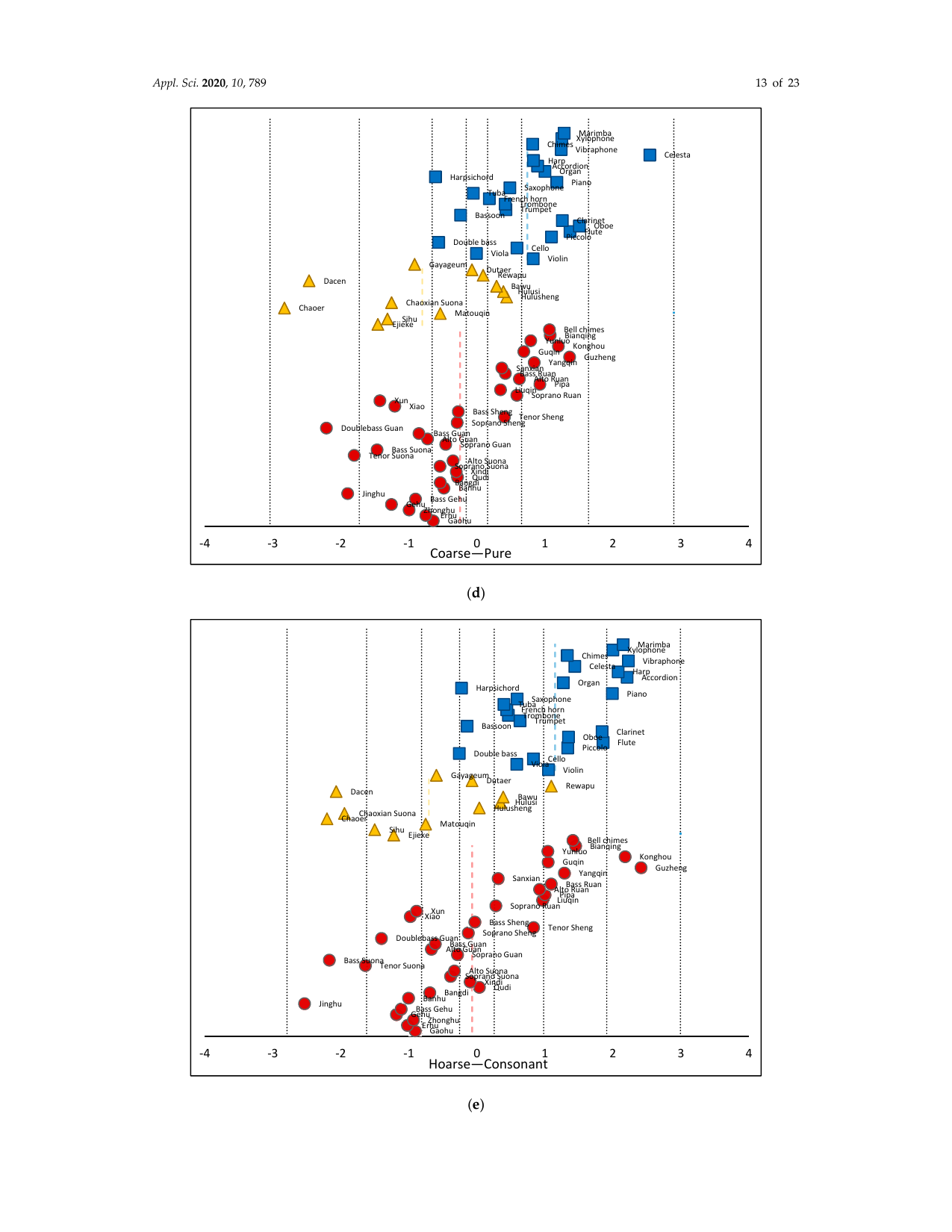
図中の青い四角は西洋管弦楽器、黄色い三角は中国少数民族楽器、赤い円は中国民族管弦楽器を表す。青・黄・赤の点線は、それぞれ各楽器群の平均値を表す。横軸ラベルの訳: Dark-Bright = 暗い-明るい、Raspy-Mellow = 干瘪した-柔らかい、Vigorous-Sharp = 渾厚-鋭い、Coarse-Pure = 粗い-純粋、Hoarse-Consonant = しわがれた-協和的。
図4から、中国楽器の音色値の分布は西洋楽器と有意に異なることが分かる。たとえば raspy/mellow と hoarse/consonant では、両者の尺度分布に大きな差が見られた。これは、中国楽器を含む本音色データベースが、従来の西洋楽器データベースよりも豊かな音色タイプを含んでいることを示唆している。また、5つの評価語対における音色サンプルの分布は比較的均衡していた。これは、提案した評価用語が複数の音色タイプを代表し、楽器間の属性差をよりよく識別できることを示しており、音色知覚特徴モデルの精度向上に役立つと考えられる。
4.4. 予測モデルの構築
本研究では、重回帰、サポートベクタ回帰、ニューラルネットワーク、ランダムフォレストを用いて、客観パラメータと主観評価データを関連づけ、音色知覚特徴の数理モデルを構築した。重回帰では変数の投入と除去にステップワイズ法を用い [68]、サポートベクタ回帰ではカーネルに放射基底関数を用いた [69]。ニューラルネットワークには隠れ層を含む多層パーセプトロンを採用した [70]。ランダムフォレストは複数の CART 系木からなる一般的なアンサンブルモデルであり、各木は元データのブートストラップ標本から成長させる [71]。
モデリング前に、予測対象属性に対する特徴選択を行った。この過程は3段階である。第1にスクリーニングで、重要でない予測子や問題のあるケースを除去する。第2にランキングで、残った予測子を並べ替え、それぞれが目的変数をどれだけ予測できるかを一変数ずつ判定する。第3に選択で、後続モデルに使う重要な特徴部分集合を決定する。
モデリングでは、データの80%を学習用、残り20%を検証用に用いた。モデル入力は166次元の客観パラメータ集合、出力は5つの知覚次元(bright/dark、raspy/mellow、sharp/vigorous、coarse/pure、hoarse/consonant)の値である。精度評価には相関係数を用い、モデル予測値と主観評価値との相関が高いほど、より高精度のモデルと判断した。
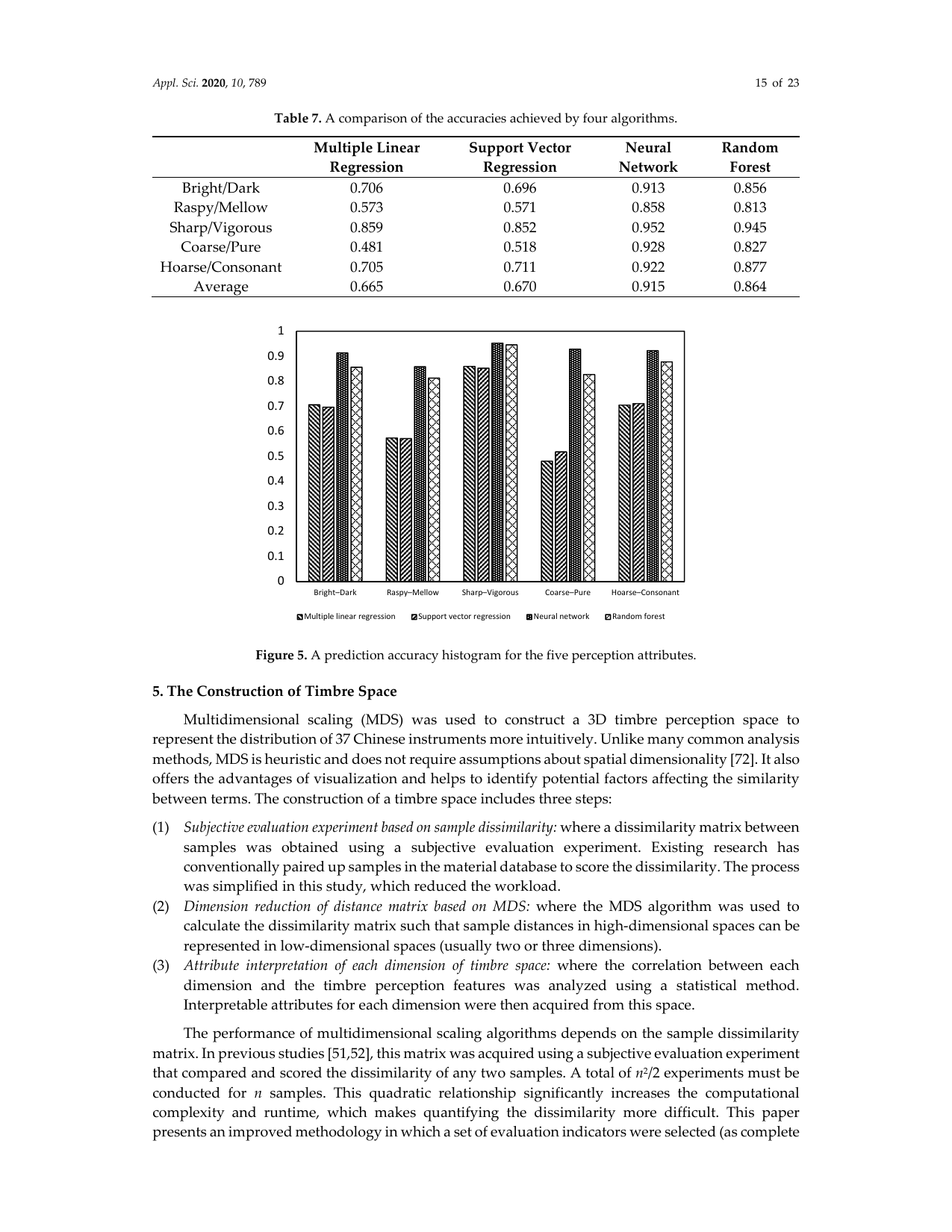
4つのアルゴリズムにおける、5つの知覚次元それぞれの予測精度を表7に示す。また、図5に次元ごとの予測精度ヒストグラムを示す。結果から、提案手法は5つの次元すべてで有効な予測を行えたことが分かる。最良のアルゴリズムでは、bright/dark、sharp/vigorous、coarse/pure、hoarse/consonant で0.9を超える精度が得られた。平均では、ニューラルネットワーク(0.915)とランダムフォレスト(0.864)が、重回帰(0.665)およびサポートベクタ回帰(0.670)を上回った。特にニューラルネットワークは、5つすべての知覚次元において高い予測精度を示した。
| 次元 | 重回帰 | サポートベクタ回帰 | ニューラルネットワーク | ランダムフォレスト |
|---|---|---|---|---|
| Bright/Dark | 0.706 | 0.696 | 0.913 | 0.856 |
| Raspy/Mellow | 0.573 | 0.571 | 0.858 | 0.813 |
| Sharp/Vigorous | 0.859 | 0.852 | 0.952 | 0.945 |
| Coarse/Pure | 0.481 | 0.518 | 0.928 | 0.827 |
| Hoarse/Consonant | 0.705 | 0.711 | 0.922 | 0.877 |
| 平均 | 0.665 | 0.670 | 0.915 | 0.864 |
5. 音色空間の構築
37種の中国楽器の分布をより直感的に表現するため、多次元尺度構成法(MDS)を用いて3次元音色知覚空間を構築した。MDS は多くの一般的分析手法とは異なり、空間次元数に関する仮定を必要としないヒューリスティックな手法である [72]。また可視化に優れ、項目間類似性に影響する潜在因子の発見にも役立つ。音色空間の構築は次の3段階から成る。
- サンプル非類似度に基づく主観評価実験: 主観評価実験によりサンプル間の非類似度行列を得る。従来研究ではサンプルを2つずつ比較して非類似度を評定していたが、本研究ではこの手順を簡略化して負荷を削減した。
- MDS に基づく距離行列の次元削減: MDS により、高次元空間でのサンプル間距離を低次元空間(通常は2次元または3次元)で表現する。
- 音色空間各次元の属性解釈: 各次元と音色知覚特徴との相関を統計的に分析し、各次元に対応する知覚属性を求める。
多次元尺度構成法の性能は、サンプル非類似度行列に依存する。従来研究 [51,52] では、任意の2サンプルを比較して非類似度を主観評価する実験により、この行列を取得していた。サンプル数を n とすると、合計 n2/2 回の比較実験が必要であり、計算負荷と作業時間が大きく、非類似度定量化を困難にしていた。本論文では、できるだけ完全な一組の評価指標を選び、各指標についてすべてのサンプルを順次評定し、その結果をサンプルの特徴ベクトルとみなして各ベクトル間距離を計算する改良法を提案した。表3の16個の音色評価語は、分析段階で各次元の属性評価にも使われた。
さらに、37種の中国楽器について、系列カテゴリー法による主観評価実験(実験C)を行った。表3の16知覚次元を対象に9段階評定を実施し、データの信頼性と妥当性を分析した。特徴ベクトル間のユークリッド距離を計算し、37サンプルの非類似度行列を得た。これを MDS で処理し、3次元音色知覚空間を構築した。
5.1. 実験C: サンプル非類似度に基づく主観評価実験
この主観評価実験に必要な音素材を準備する際、サンプル選定では3つの要因を考慮した [73]。第1に適切なサンプル数である。MDS の精度とモデル拘束の十分性を担保するには、サンプル数が十分に多い必要がある。厳密な決定規則を設けるのは難しいが、多くの MDS ベースの音色研究では、2次元空間なら少なくとも10サンプル、3次元空間なら少なくとも15サンプルが必要とされる [51,74,75]。本研究では37種の中国楽器を用い、MDS モデルに十分な拘束を与えた。
第2に音色変動範囲である。対象の音色範囲が広いほど、構築されたモデルは新たな音色サンプルにもより広く適用できる [34]。図4から分かるように、中国楽器は西洋楽器よりも音色評価尺度上でより広い分布範囲を示しており、本研究の中国楽器サンプルは豊かな音色多様性を確保している。第3にサンプル分布の均一性である。各知覚属性における音サンプルの分布は、できるだけ均一であることが望ましい。音色空間は連続的な知覚空間であり、均一に分布したサンプル集合はその構築に有利である。非均一分布は MDS の解を劣化させ、クラス間構造が十分に表れない原因となる [76]。図4に示すように、本研究のサンプルは多様な音色属性を広く覆い、心理尺度上でも均一性を備えていた。
実験環境と被験者条件は実験Bと同様である。手続きとしては、各実験サンプルを再生しながら、被験者が16個の音色知覚特徴(音色評価語)について順に心理尺度を判断し、各項目を9点尺度で評定した。
5.2. MDS を用いた3次元音色空間の構築
実験データの信頼性・妥当性の処理方法は、実験Bと同じである。処理後データを平均し、各サンプルについて各評価語に対する全被験者の平均得点を算出した。これらのデータを使って、距離行列の形で表される音色非類似度を計算した。本論文では、被験者間の個人差を考慮し、各評定に対応する重みを割り当てる MDS アルゴリズム [77] を採用した。これにより、あらゆる次元の用語を考慮し、実験データをより完全に活用できる。2サンプル間の音色属性空間における非類似度は、次の距離行列として表される。
式(8)
d'_{ijk} = √( Σ[r=1..R] w_ir · (x_jr - x_kr)^2 )
ここで d'_{ijk} は被験者 i が音 j と音 k を評価したときの非類似度スコア、w_ir は r 次元における被験者 i の重み、x_kr は r 次元におけるサンプル k の座標を表す。
式(8) により、37個の音色特徴ベクトル間の距離を計算し、37サンプルの非類似度距離行列を得た(補足資料参照)。これを MDS の入力とし、先行研究 [51,52] を参照して音色空間の次元数を決めた。Kruskal の stress 関数 [78] に基づき、音色空間は3次元と判断した。MDS を用いて非類似度距離行列を次元削減することで、各音サンプルの3次元音色空間内座標を得た(図6)。
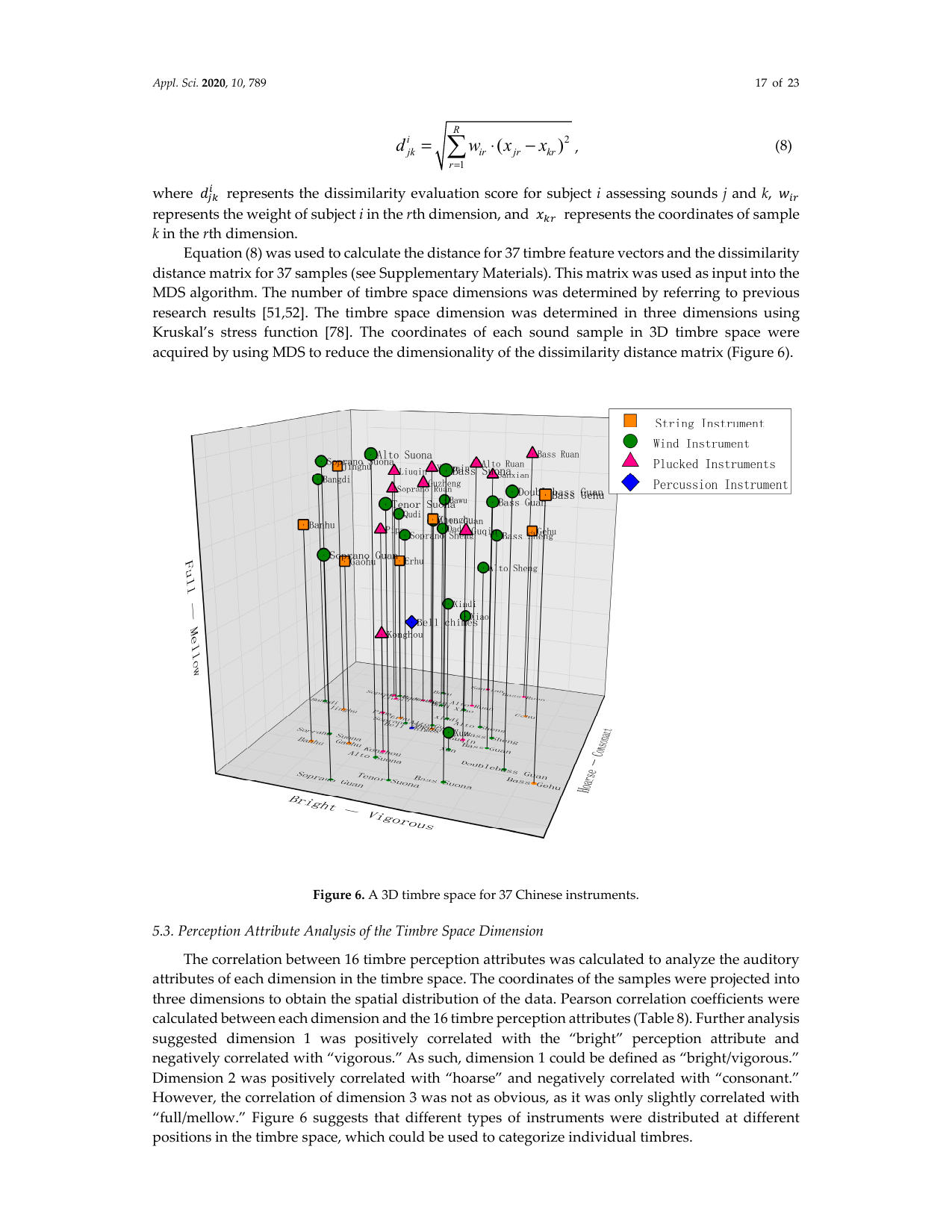
図中凡例: String Instruments = 弦楽器、Wind Instruments = 管楽器、Plucked Instruments = 撥弦楽器、Percussion Instruments = 打楽器。
5.3. 音色空間次元の知覚属性分析
音色空間における各次元の聴覚属性を分析するため、16個の音色知覚属性との相関を計算した。サンプル座標を3次元に投影して空間分布を求め、各次元と16属性の Pearson 相関係数を算出した(表8)。その結果、第1次元は「明るい」と正相関し、「渾厚」と負相関したため、第1次元は「明るい/渾厚」と定義できると考えられた。第2次元は「嘶哑(しわがれた)」と正相関し、「協和的」と負相関した。一方、第3次元の相関はそれほど明確ではなく、「丰满/柔和(豊満/柔和)」とわずかに相関するにとどまった。図6は、異なる楽器タイプが音色空間の異なる位置に分布していることを示しており、個々の音色の分類に利用できることを示唆している。
| 属性 | 次元1 | 次元2 | 次元3 |
|---|---|---|---|
| 纤细 (Slim) | 0.97 | -0.13 | -0.11 |
| 明亮 (Bright) | 0.97 | -0.17 | 0.15 |
| 暗淡 (Dark) | -0.96 | 0.19 | -0.14 |
| 尖锐 (Sharp) | 0.95 | 0.23 | 0.14 |
| 浑厚 (Vigorous) | -0.99 | -0.05 | 0.11 |
| 单薄 (Thin) | 0.94 | 0.26 | -0.10 |
| 厚实 (Thick) | -0.97 | 0.00 | 0.22 |
| 清脆 (Silvery) | 0.96 | -0.22 | 0.04 |
| 干瘪 (Raspy) | 0.39 | 0.87 | 0.02 |
| 丰满 (Full) | -0.83 | -0.38 | 0.33 |
| 粗糙 (Coarse) | -0.35 | 0.89 | -0.06 |
| 纯净 (Pure) | 0.34 | -0.82 | 0.11 |
| 嘶哑 (Hoarse) | -0.15 | 0.93 | -0.13 |
| 协和 (Consonant) | -0.02 | -0.96 | 0.00 |
| 柔和 (Mellow) | -0.38 | -0.80 | -0.37 |
| 混浊 (Muddy) | -0.91 | 0.26 | -0.16 |
6. 結論
本研究では、楽音における音色知覚特徴の分析とモデリングのための新しい方法論を提示した。主要な貢献は次の3点に要約できる。
- 中国語文脈における2組の音色評価用語体系を構築する新しい方法を提案した。主観評価実験の結果、これらの用語は異なる楽器間の音色差を適切に識別できることが示された。
- 関連基準に従って72種の楽器を含む音色素材ライブラリを構築した。系列カテゴリー法による主観評価実験を実施し、5組の知覚次元における心理尺度を得た。その後、重回帰、サポートベクタ回帰、ニューラルネットワーク、ランダムフォレストを用いて音色知覚特徴の数理モデルを構築した。結果は、このモデルが新しいサンプルの知覚特徴を予測できることを示した。
- 改良された3次元音色空間構築法を提案し、37種の中国楽器に対して MDS により実証した。音色空間3次元と16知覚属性の相関分析により、それぞれの聴覚知覚属性を決定した。
今後の研究では、次の3点に注力する。第1に、既存の音色データベースを基に補足サンプルを追加し、データの多様性と量を拡張してモデルの一貫性と頑健性を向上させる。第2に、主観評価実験や統計分析を用いて、音色の本質属性をより正確に反映する評価語を選定し、簡潔で効果的な音色空間構築を支援する。第3に、主観評価データをさらに増やして機械学習アルゴリズムを改良し、追加の相関アルゴリズムも試験して予測精度を向上させる。最終的には音色空間各次元に対する数理モデリングを行い、西洋楽器など他の楽器群の分布と中国楽器の分布を比較して、共通パターンを明らかにしたい。
補足情報
著者貢献: 調査、概念化、方法論、データキュレーション、執筆(初稿、レビュー、編集)は J.L.; プロジェクト管理と監督は W.J., Y.J., S.W.; ソフトウェア、実験実施、データ処理は J.L. と X.Z.。すべての著者は公表版を読み、同意した。
研究資金: 本研究は文化和旅游部重点実験室研究資金(WHB1801)の支援を受けた。
利益相反: 著者らは利益相反がないことを宣言する。
付録A
第2.1節で言及した音色素材には72種の楽器が含まれ、中国民族管弦楽器37種、中国少数民族楽器11種、西洋管弦楽器24種から成る(表A1)。中国民族管弦楽器および中国少数民族楽器の名称は、中国語原表記と英訳を併記する。
| カテゴリ | タイプ | 楽器名 |
|---|---|---|
| 中国民族管弦楽器 (37) | 擦弦楽器 (7) | 高胡 (Gaohu)、二胡 (Erhu)、中胡 (Zhonghu)、革胡 (Gehu)、低音革胡 (Bass Gehu)、京胡 (Jinghu)、板胡 (Banhu) |
| 中国民族管弦楽器 (37) | 吹奏楽器 (17) | 梆笛 (Bangdi)、曲笛 (Qudi)、新笛 (Xindi)、高音笙 (Soprano Sheng)、中音笙 (Tenor Sheng)、低音笙 (Bass Sheng)、高音唢呐 (Soprano Suona)、中音唢呐 (Alto Suona)、次中音唢呐 (Tenor Suona)、低音唢呐 (Bass Suona)、高音管 (Soprano Guan)、中音管 (Alto Guan)、低音管 (Bass Guan)、倍低音管 (Doublebass Guan)、埙 (Xun)、箫 (Xiao)、巴乌 (Bawu) |
| 中国民族管弦楽器 (37) | 撥弦楽器 (10) | 小阮 (Soprano Ruan)、中阮 (Alto Ruan)、大阮 (Bass Ruan)、柳琴 (Liuqin)、琵琶 (Pipa)、扬琴 (Yangqin)、古筝 (Guzheng)、古琴 (Guqin)、箜篌 (Konghou)、三弦 (Sanxian) |
| 中国民族管弦楽器 (37) | 打楽器 (3) | 编钟 (Bell chimes)、编磬 (Bianqing)、云锣 (Yunluo) |
| 中国少数民族楽器 (11) | 擦弦楽器 (4) | 艾捷克 (Ejieke)、四胡 (Sihu)、马头琴 (Matouqin)、潮尔 (Chaoer) |
| 中国少数民族楽器 (11) | 吹奏楽器 (4) | 朝鲜唢呐 (Chaoxian Suona)、葫芦笙 (Hulusheng)、葫芦丝 (Hulusi)、大岑 (Dacen) |
| 中国少数民族楽器 (11) | 撥弦楽器 (3) | 热瓦普 (Rewapu)、都塔尔 (Dutaer)、伽倻琴 (Gayageum) |
| 西洋管弦楽器 (24) | 擦弦楽器 (4) | Violin、Viola、Cello、Double bass |
| 西洋管弦楽器 (24) | 木管楽器 (6) | Piccolo、Flute、Oboe、Clarinet、Bassoon、Saxophone |
| 西洋管弦楽器 (24) | 金管楽器 (4) | Trumpet、Trombone、French horn、Tuba |
| 西洋管弦楽器 (24) | 鍵盤楽器 (4) | Piano、Harpsichord、Organ、Accordion |
| 西洋管弦楽器 (24) | 撥弦楽器 (1) | Harp |
| 西洋管弦楽器 (24) | 打楽器 (5) | Celesta、Vibraphone、Chimes、Xylophone、Marimba |
参考文献
参考文献は書誌検索性を優先し、原文表記を保持した。
- Chen, X. Sound and Hearing Perception. China Broadcasting and Television Press: Beijing, 2006.
- Moore, B.C.; Glasberg, B.R.; Baer, T. A model for the prediction of thresholds, loudness, and partial loudness. J. Audio Eng. Soc. 1997, 45, 224-240.
- Meddis, R.; O’Mard, L. A unitary model of pitch perception. J. Acoust. Soc. Am. 1997, 102, 1811-1820. DOI:10.1121/1.420088.
- Patel, A.D. Music, Language, and the Brain. Oxford University Press: Oxford, England, UK, 2010.
- ANSI S1.1-1994. American National Standard Acoustical Terminology. Acoustical Society of America New York, 1994.
- Zwicker, E.; Fastl, H. Psychoacoustics: Facts and Models. Springer Science & Business Media: 2013; Vol. 22.
- Cermak, G.W.; Cornillon, P.C. Multidimensional analyses of judgments about traffic noise. J. Acoust. Soc. Am. 1976, 59, 1412-1420. DOI:10.1121/1.381029.
- Kuwano, S.; Namba, S.; Fastl, H.; Schick, A. Evaluation of the impression of danger signals-comparison between Japanese and German subjects. In Contributions to Psychological Acoustics, Schick, A.; Klatte, M., Eds. BIS: Oldenburg, 1997; pp. 115-128.
- Iwamiya, S.-i.; Zhan, M. A comparison between Japanese and Chinese adjectives which express auditory impressions. J. Acoust. Soc. Jpn. (E) 1997, 18, 319-323. DOI:10.1250/ast.18.319.
- Stepanek, J. Relations between perceptual space and verbal description in violin timbre. acústica 2004 Guimarães 2004, 077.
- Kim, S.; Bakker, R.; Ikeda, M. Timbre preferences of four listener groups and the influence of their cultural backgrounds, Audio Engineering Society: Audio Engineering Society Convention 140, 2016.
- Solomon, L.N. Semantic Approach to the Perception of Complex Sounds. J. Acoust. Soc. Am. 1958, 30, 421-425. DOI:10.1121/1.1909632.
- von Bismarck, G. Timbre of steady sounds: A factorial investigation of its verbal attributes. Acta Acust. United Acust. 1974, 30, 146-159.
- Pratt, R.L.; Doak, P.E. A subjective rating scale for timbre. J. Sound Vibrat. 1976, 45, 317-328. DOI:10.1016/0022-460x(76)90391-6.
- Namba, S.; Kuwano, S.; Hatoh, T.; Kato, M. Assessment of musical performance by using the method of continuous judgment by selected description. Music Percept. 1991, 8, 251-275. DOI:10.2307/40285502.
- Ethington, R.; Punch, B. SeaWave: A system for musical timbre description. Comput. Music J. 1994, 18, 30-39. DOI:10.2307/3680520.
- Faure, A.; Mcadams, S.; Nosulenko, V. Verbal correlates of perceptual dimensions of timbre. In 4th International Conference on Music Perception and Cognition, Montréal, Canada, 1996.
- Howard, D.M.; Tyrrell, A.M. Psychoacoustically informed spectrography and timbre. Organised Sound 1997, 2, 65-76. DOI:10.1017/S1355771897009011.
- Shibuya, K.; Koyama, T.; Sugano, S. The relationship between KANSEI and bowing parameters in the scale playing on the violin. In IEEE SMC’99 Conference Proceedings, IEEE: Tokyo, Japan, 1999; Vol. 4, pp. 305-310.
- Kuwano, S.; Namba, S.; Schick, A.; Hoege, H.; Fastl, H.; Filippou, T.; Florentine, M.; Muesch, H. The timbre and annoyance of auditory warning signals in different countries. In Proc. INTERNOISE 2000, Nice, France, 2000.
- Disley, A.C.; Howard, D.M. Timbral semantics and the pipe organ. In Proceedings of the Stockholm Music Acoustic Conference 2003, Stockholm, Sweden, 2003; pp. 607-610.
- Moravec, O.; Štepánek, J. Verbal description of musical sound timbre in Czech language. In Proceedings of the Stockholm Music Acoustic Conference 2003, Stockholm, Sweden, 2003; pp. SMAC-1-SMAC-4.
- Collier, G.L. A comparison of novices and experts in the identification of sonar signals. Speech Commun. 2004, 43, 297-310. DOI:10.1016/j.specom.2004.03.003.
- Martens, W.L.; Marui, A. Constructing individual and group timbre spaces for sharpness-matched distorted guitar timbres, Audio Engineering Society Convention 119, 2005.
- Disley, A.C.; Howard, D.M.; Hunt, A.D. Timbral description of musical instruments. In International Conference on Music Perception and Cognition, Bologna, Italy, 2006; pp. 61-68.
- Stepánek, J. Musical sound timbre: Verbal description and dimensions. In Proceedings of the 9th International Conference on Digital Audio Effects (DAFx-06), Montreal, Canada, 2006; pp. 121-126.
- Katz, B.; Katz, R.A. Mastering Audio: The Art and the Science. 2nd ed.; Focal Press: Oxford, 2007.
- Howard, D.; Disley, A.; Hunt, A. Towards a music synthesizer controlled by timbral adjectives. In Proceedings of 14th International Congress on Sound & Vibration, Cairns, Australia, 2007.
- Barbot, B.; Lavandier, C.; Cheminée, P. Perceptual representation of aircraft sounds. Appl. Acoust. 2008, 69, 1003-1016. DOI:10.1016/j.apacoust.2007.07.001.
- Pedersen, T.H. The Semantic Space of Sounds. Delta: 2008.
- Alluri, V.; Toiviainen, P. Exploring perceptual and acoustical correlates of polyphonic timbre. Music Percept. 2010, 27, 223-242. DOI:10.1525/mp.2010.27.3.223.
- Fritz, C.; Blackwell, A.F.; Cross, I.; Woodhouse, J.; Moore, B.C. Exploring violin sound quality: Investigating English timbre descriptors and correlating resynthesized acoustical modifications with perceptual properties. J. Acoust. Soc. Am. 2012, 131, 783-794. DOI:10.1121/1.3651790.
- Altinsoy, M.E.; Jekosch, U. The semantic space of vehicle sounds: Developing a semantic differential with regard to customer perception. J. Audio Eng. Soc. 2012, 60, 13-20.
- Elliott, T.M.; Hamilton, L.S.; Theunissen, F.E. Acoustic structure of the five perceptual dimensions of timbre in orchestral instrument tones. J. Acoust. Soc. Am. 2013, 133, 389-404. DOI:10.1121/1.4770244.
- Zacharakis, A.; Pastiadis, K.; Reiss, J.D. An interlanguage study of musical timbre semantic dimensions and their acoustic correlates. Music Percept. 2014, 31, 339-358. DOI:10.1525/mp.2014.31.4.339.
- Skovenborg, E. Development of semantic scales for music mastering, Audio Engineering Society: Audio Engineering Society Convention 141, 2016.
- Wallmark, Z. A corpus analysis of timbre semantics in orchestration treatises. Psychol. Music 2019, 47, 585-605. DOI:10.1177/0305735618768102.
- Chen, K.-A.; Wang, N.; Wang, J.-C. Investigation on human ear’s capability for identifing non-speech objects. Acta Phys. Sin. 2009, 58, 5075-5082. DOI:10.3321/j.issn:1000-3290.2009.07.111.
- Herrera-Boyer, P.; Peeters, G.; Dubnov, S. Automatic classification of musical instrument sounds. J. New Music Res. 2003, 32, 3-21. DOI:10.1076/jnmr.32.1.3.16798.
- Bowman, C.; Yamauchi, T. Perceiving categorical emotion in sound: The role of timbre. Psychomusicology: Music, Mind, and Brain 2016, 26, 15-25. DOI:10.1037/pmu0000105.
- Gupta, C.; Li, H.; Wang, Y. Perceptual evaluation of singing quality. In 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), IEEE: Kuala Lumpur, Malaysia, 2017; pp. 577-586.
- Allen, N.; Hines, P.C.; Young, V.W. Performances of human listeners and an automatic aural classifier in discriminating between sonar target echoes and clutter. J. Acoust. Soc. Am. 2011, 130, 1287-1298. DOI:10.1121/1.3614549.
- Wang, N.; Chen, K.-A. Regression model of timbre attribute for underwater noise and its application to target recognition. Acta Phys. Sin. 2010, 59, 2873-2881.
- Blauert, J. Communication Acoustics. Springer: Berlin, Heidelberg, 2005; Vol. 2.
- Jensen, K. Timbre Models of Musical Sounds. Ph.D dissertation, Department of Computer Science, University of Copenhagen, Copenhagen, Denmark, 1999.
- Desainte-Catherine, M.; Marchand, S. Structured additive synthesis: Towards a model of sound timbre and electroacoustic music forms. In Proceedings of the International Computer Music Conference (ICMC99), China, 1999; pp. 260-263.
- Aucouturier, J.J.; Pachet, F.; Sandler, M. “The way it sounds”: Timbre models for analysis and retrieval of music signals. IEEE Trans. Multimedia 2005, 7, 1028-1035. DOI:10.1109/tmm.2005.858380.
- Burred, J.; Röbel, A.; Rodet, X. An accurate timbre model for musical instruments and its application to classification. In Learning the Semantics of Audio Signals, Proceedings of the First International Workshop, LSAS 2006, Athens, Greece, 2006; pp. 22-32.
- Wang, X.; Meng, Z. The consonance evaluation method of Chinese plucking instruments. Acta Acust. 2013, 38, 486-492.
- Sciabica, J.-F.; Bezat, M.-C.; Roussarie, V.; Kronland-Martinet, R.; Ystad, S. Towards the timbre modeling of interior car sound. In Proceedings of the 15th International Conference on Auditory Display, Copenhagen, Denmark, 2009.
- Grey, J.M. Multidimensional perceptual scaling of musical timbres. J. Acoust. Soc. Am. 1977, 61, 1270-1277. DOI:10.1121/1.381428.
- McAdams, S.; Winsberg, S.; Donnadieu, S.; De Soete, G.; Krimphoff, J. Perceptual scaling of synthesized musical timbres: Common dimensions, specificities, and latent subject classes. Psychol. Res. 1995, 58, 177-192. DOI:10.1007/bf00419633.
- Martens, W.L.; Giragama, C.N. Relating multilingual semantic scales to a common timbre space, Audio Engineering Society Convention 113, 2002.
- Martens, W.L.; Giragama, C.N.; Herath, S.; Wanasinghe, D.R.; Sabbir, A.M. Relating multilingual semantic scales to a common timbre space-Part II, Audio Engineering Society Convention 115, 2003.
- Zacharakis, A.; Pastiadis, K. Revisiting the luminance-texture-mass model for musical timbre semantics: A confirmatory approach and perspectives of extension. J. Audio Eng. Soc. 2016, 64, 636-645. DOI:10.17743/jaes.2016.0032.
- Simurra Sr, I.; Queiroz, M. Pilot experiment on verbal attributes classification of orchestral timbres, Audio Engineering Society Convention 143, 2017.
- Melara, R.D.; Marks, L.E. Interaction among auditory dimensions: Timbre, pitch, and loudness. Percept. Psychophys. 1990, 48, 169-178. DOI:10.3758/bf03207084.
- Zhu, J.; Liu, J.; Li, Z. Research on loudness balance of Chinese national orchestra instrumental sound. In Proceedings of the 2018 national acoustical congress of physiological acoustics, psychoacoustics, music acoustics, Beijing, China, 2018; pp. 34-35.
- EBU – TECH 3253. Sound Quality Assessment Material Recordings for Subjective Tests. Users’ handbook for the EBU SQAM CD. EBU: Geneva, 2008.
- Alías, F.; Socoró, J.; Sevillano, X. A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Appl. Sci. 2016, 6, 143. DOI:10.3390/app6050143.
- Peeters, G. A large set of audio features for sound description (similarity and classification). CUIDADO IST Project Report 2004, 54, 1-25.
- Peeters, G.; Giordano, B.L.; Susini, P.; Misdariis, N.; McAdams, S. The timbre toolbox: Extracting audio descriptors from musical signals. J. Acoust. Soc. Am. 2011, 130, 2902-2916. DOI:10.1121/1.3642604.
- Pollard, H.F.; Jansson, E.V. A tristimulus method for the specification of musical timbre. Acta Acust. United Acust. 1982, 51, 162-171.
- Krimphoff, J.; McAdams, S.; Winsberg, S. Caractérisation du timbre des sons complexes.II. Analyses acoustiques et quantification psychophysique. J. Phys. IV 1994, 4, C5-625-C625-628. DOI:10.1051/jp4:19945134.
- Scheirer, E.; Slaney, M. Construction and evaluation of a robust multifeature speech/music discriminator. In 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 1997; pp. 1331-1334.
- Lartillot, O. MIRtoolbox 1.7.2 User’s Manual. RITMO Centre for Interdisciplinary Studies in Rhythm, Time and Motion, University of Oslo: Norway, 2019.
- Meng, Z. Experimental Psychological Method for Subjective Evaluation of Sound Quality. National defence of Industry Press: Beijing, 2008.
- Hodeghatta, U.R.; Nayak, U. Multiple linear regression. In Business Analytics Using R - A Practical Approach, Apress: Berkeley, CA, 2017; pp. 207-231.
- Yeh, C.-Y.; Huang, C.-W.; Lee, S.-J. A multiple-kernel support vector regression approach for stock market price forecasting. Expert Syst. Appl. 2011, 38, 2177-2186. DOI:10.1016/j.eswa.2010.08.004.
- Haykin, S.S. Neural Networks and Learning Machines. 3rd ed.; Pearson education: Upper Saddle River, 2009.
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann Publishers, Inc.: San Francisco, CA, USA, 2016.
- Borg, I.; Groenen, P.J.; Mair, P. Applied Multidimensional Scaling. Springer Science & Business Media: Berlin, Heidelberg, 2012.
- Chen, K.-A. Auditory Perception and Automatic Recognition of Environmental Sounds. Science Press: Beijing, 2014.
- Susini, P.; McAdams, S.; Winsberg, S.; Perry, I.; Vieillard, S.; Rodet, X. Characterizing the sound quality of air-conditioning noise. Appl. Acoust. 2004, 65, 763-790. DOI:10.1016/j.apacoust.2004.02.003.
- Tucker, S. An Ecological Approach to the Classification of Transient Underwater Acoustic Events: Perceptual Experiments and Auditory Models. University of Sheffield, Sheffield, UK, 2003.
- Shepard, R.N. Representation of structure in similarity data: Problems and prospects. Psychometrika 1974, 39, 373-421. DOI:10.1007/bf02291665.
- Borg, I.; Groenen, P.J.F.; Mair, P. Variants of different MDS models. In Applied Multidimensional Scaling. SpringerBriefs in Statistics, Springer: Berlin, Heidelberg, 2013; pp. 37-47.
- Borg, I.; Groenen, P. Modern multidimensional scaling: Theory and applications. J. Educ. Meas. 2003, 40, 277-280. DOI:10.1111/j.1745-3984.2003.tb01108.x.

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.